[Python] 파이썬 판다스(Pandas) - NaN 비어 있는 데이터 다루는 방법

NaN이란?
NaN은 "Not a Number"의 약자로, 결측치(missing value)를 나타내는 데 사용되는 특수한 값이다. 주로 파이썬의 판다스와 같은 데이터 분석 도구에서 사용된다.
NaN은 데이터셋에서 값이 존재하지 않거나 수학적으로 정의할 수 없는 상태를 나타낸다. 이것은 데이터의 부재, 누락, 또는 특정 연산 결과가 정의되지 않는 경우에 해당한다.
먼제 데이터프레임을 통해 NaN 데이터를 알아보자.
>> items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes':8, 'suits':45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5, 'shirts': 2, 'shoes':5, 'suits':7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes':10}]
>> df=pd.DataFrame(data= items2, index= ['store 1','store 2','store 3'])
>> df
NaN를 파악하는 방법
isna() 메소드를 사용하면 NaN 이 해당된 셀은 true로 나타낸다.
>> #변수명.isna
>> df.isna()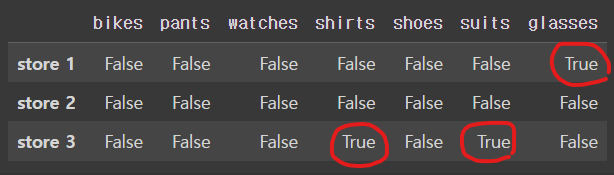
거꾸로 알고 싶다면 notna() 메소드를 사용한다.
true(값이 있는 것, NaN이 아닌 것), false(값이 NaN인 것)
>> df.notna()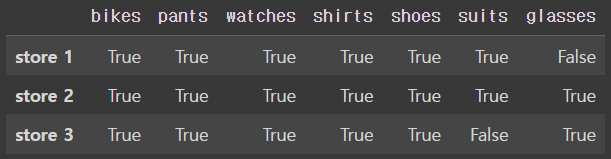
그리고 컬럼별로 NaN 의 개수를 알고 싶다면 sum() 메소드를 추가하여 실행한다.
>> df.isna().sum()
bikes 0
pants 0
watches 0
shirts 1
shoes 0
suits 1
glasses 1
dtype: int64전체 데이터에서 NaN 의 개수를 알고 싶다면 sum() 메소드를 한번 더 추가한다.
>> df.isna().sum().sum()
3
NaN를 처리하는 방법
1. NaN를 삭제하는 방법
비어있는 데이터를 찾아내어 그 행을 삭제한다.(보통 열을 삭제한다기 보단 행을 삭제 하기 때문에)
>> df.dropna()
2. 특정 값으로 채우는 방법
NaN 데이터가 포함된 행을 삭제할 수 없다면 채우는 방법을 사용해야한다.
NaN를 숫자를 0으로 채우기
fillna() 함수를 사용하면 NaN 데이터를 0으로 채워 NaN를 없앨 수 있다.
>> df.fillna(0)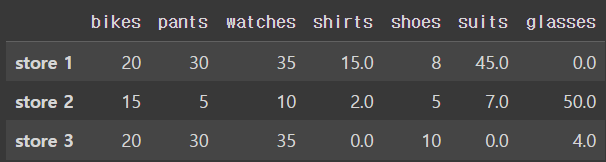
NaN를 문자 '데이터 없음'으로 채우기
0 대신 문자열 데이터를 넣어서 원하는 문자열로 대체할 수 있다.
>> df.fillna('데이터 없음')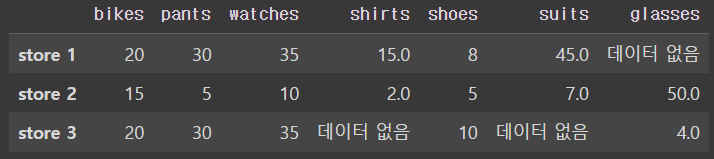
특정 NaN 데이터만 변경하기
만약 shirts 컬럼의 NaN만 변경하고 싶다면
shirts 컬럼만 지정하여 NaN 데이터를 변경할 수 있다.
>> df['shirts'].fillna('No data')
store 1 15.0
store 2 2.0
store 3 No data
Name: shirts, dtype: object
앞이나 뒤의 데이터를 이용하여 채우기
앞의 행을 데이터로 채우는 방법은 fillna 메소드의 ffill속성을 사용하고 (앞에 f는 forward)
뒤의 행을 데이터로 채우는 방법은 bfill속성을 사용한다. (b는 back)
axis 속성은 값에 따라 행열 방향을 지정할 수 있다.
axis=0: 열 방향으로 작동
axis=1: 행 방향으로 작동
>> df.fillna(method= 'ffill', axis=0)
각 컬럼별 평균값, 최소값, 최대값으로 채우기
mean() 메소드는 판다스에서 Series나 DataFrame의 평균을 계산하는 데 사용된다. 이 메소드는 주어진 축을 따라 평균을 계산한다.
>> df.mean()
bikes 18.333333
pants 21.666667
watches 26.666667
shirts 8.500000
shoes 7.666667
suits 26.000000
glasses 27.000000
dtype: float64
>> df.fillna(df.mean()) # 평균 구한다음에 Nan 값 자동으로 들어감
>> df.fillna(df.max()) #최대값으로 채우기
>> df.fillna(df.min()) #최소값으로 채우기